Much of modern cryptographic education emphasizes formal definitions, such as Shannon’s characterization of perfect secrecy. These are often presented as fixed endpoints rather than models derived from specific assumptions.
The system we present here emerged from an implementation-driven approach, where the design process was guided by the practical goal of eliminating observable information leakage during decryption, rather than by satisfying a predefined formalism. This raises a broader question: "Should perfect secrecy be understood exclusively through its classical probabilistic formulation, or can it also be realized operationally in systems that achieve the same informational outcome through different structural mechanisms?" We argue that exploring such alternatives not only deepens our understanding of perfect secrecy but also enriches the theoretical framework itself.
Rather than redefining Shannon's result, this work invites examinations of whether alternative constructions can realize the same condition: I(P;C) = 0, and how such systems should be interpreted within the existing theoretical framework.
To clarify any misunderstanding from the outset, we do not oppose Shannon’s work. Instead, we seek to expand the discussion and frame our approach as an exploration of possibilities, not a contradiction. Shannon tells us when perfect secrecy exists, but the question of how, and whether alternative mechanisms can achieve the same outcome remains open.
-----*-----
To achieve OTP security we need:
1. A Key that is truly random
2. A Key as long as "All" messages to be sent
3. Each part of the Key is only used once
4. The Key is kept completely secret
To achieve security with our system we need:
1. A random permutation of n! possible permutations (characters in
chosen alphabet provide possible permutation).
2. The permutation is kept completely secret.
OTP :
We will use the 26-character English alphabet and add a space character and a punctuation mark. With that, the modulus changes from 26 to 28 when using modular arithmetic. The text we encrypt: HELLO WORLD.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | . |
| Plaintext | H(07) | E(04) | L(11) | L(11) | 0(14) | (26) | W(22) | O(14) | R(17) | L(11) | D(03) | .(27) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| + Key | M(12) | Q(16) | W(22) | C(02) | J(09) | O(14) | T(19) | B(01) | K(10) | N(13) | P(15) | Z(25) |
| = | = 19 | = 20 | = 33 | = 13 | = 23 | = 40 | = 41 | = 15 | = 27 | = 24 | = 18 | = 52 |
| mod28 | T(19) | U(20) | F(05) | N(13) | X(23) | M(12) | N(13) | P(15) | .(27) | Y(24) | S(18) | Y(24) |
| Plaintext: | H | E | L | L | O | W | O | R | L | D | . | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Key: | M | Q | W | C | J | O | T | B | K | N | P | Z |
| Cipher: | T | U | F | N | X | M | N | P | . | Y | S | Y |
We have a plaintext, a key, a cipher, but have created now another problem, which in cryptography is called the key distribution problem. We have to find an absolute secure channel to transmit the key, enabling a lawful recipient of our cipher to decrypt it. We also notice that the amount of data we have to transmit has doubled when comparing it with the plaintext.
Let's find out if our system can change the one assumption for the OTP, that according to experts makes it useless (key length and the secure transmission of it) and still comply with Shannon's theorem I(P;C)=0.
-----*-----
Our system :
We will use the 16-character hexadecimal alphabet. We don't use modular arithmetic. Each mapping step generates the next permutation (rearranged), which is then used for the following lookup. The text is again: HELLO WORLD. - H(48) E(45) L(4C) L(4C) O(4F) (20) W(57) O(4F) R(52) L(4C) D(44) .(2E)
1. Start and key permutations are chosen (random).
2. Plaintext is mapped on the current permutation.
3. Substring from the front to that character is
taken, reversed, and appended to the end.
4. Index values are recorded.
5. Loops are applied to the index sequence.
6. Key character is added (1/16 shift).
7. Cipher characters are produced.
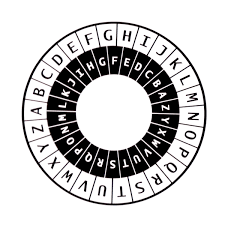
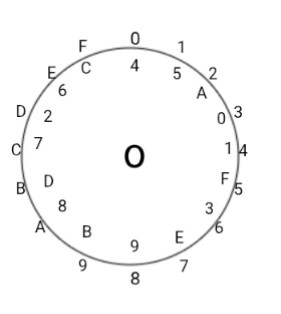
The images below show two Alberti Disks, one with the English alphabet and the second one with the hexadecimal alphabet. On the disk outside of the disks, we have placed the alphabet ordered A - Z and from 0 to F clockwise, on the inside the alphabets (randomized in the hexadecimal disk). It is intended to help readers to understand the steps taken in our system during encryption.
Before we start to encrypt our example text, let's talk about the requirment for it to proceed and the modus operandi. We have a shared secret with the recipient and he/she would require the start and key permutations.
Secret hex
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
Start Permutation
C
6
2
7
D
8
B
9
E
3
F
1
0
4
5
A
Key Permutation;
7
8
D
C
2
6
5
0
9
F
3
E
1
B
A
4
Point S = 5 - Point E = 8 | 0 + 8 = 8 (cipher); |
Hex
0
1
2
3
4
5
6
7
8
9
A
B
C
D
E
F
Permutation
C
6
2
7
D
8
B
9
E
3
F
1
0
4
5
A
<-
8
Iteration 0001
8
B
9
E
3
F
1
0
4
5
A
D
7
2
6
C
<-
4
New permutation 45AD726C01F3E9B8
Point S = 1 - Point E = F | 0 + 15 = 15 (cipher); |
Iteration 0002
4
5
A
D
7
2
6
C
0
1
F
3
E
9
B
8
<-
5
Iteration 0003
5
A
D
7
2
6
C
0
1
F
3
E
9
B
8
4
<-
4
New permutation 48B9E3F10C627DA5
Point S = 9 - Point E = F | 0 + 15 = 15 (cipher); |
Iteration 0004
4
8
B
9
E
3
F
1
0
C
6
2
7
D
A
5
<-
C
Iteration 0005
C
6
2
7
D
A
5
0
1
F
3
E
9
B
8
4
<-
4
New permutation 48B9E3F105AD726C
Point S = F - Point E = F | 0 + 15 = 15 (cipher); |
Iteration 0006
4
8
B
9
E
3
F
1
0
5
A
D
7
2
6
C
<-
C
Iteration 0007
C
6
2
7
D
A
5
0
1
F
3
E
9
B
8
4
<-
4
New permutation 48B9E3F105AD726C
Point S = 6 - Point E = 7 | 0 + 7 = 7 (cipher); |
Iteration 0008
4
8
B
9
E
3
F
1
0
5
A
D
7
2
6
C
<-
F
Iteration 0009
F
1
0
5
A
D
7
2
6
C
3
E
9
B
8
4
<-
2
New permutation 26C3E9B847DA501F
Point S = 0 - Point E = 0 | 0 + 0 = 0 (cipher); |
Iteration 0010
2
6
C
3
E
9
B
8
4
7
D
A
5
0
1
F
<-
0
Iteration 0011
0
1
F
5
A
D
7
4
8
B
9
E
3
C
2
6
<-
4
Encryption / Decryption completed - Cipher: 8FFF70
1. Account for the possible key removals.
2. Derive the possible index values that derive.
3. Consider the pair expansions represented by those indexes.
4. Account for unknown loop counts.
5. Determine whether a unique start permutation can be derived
or whether multiple or all plaintext histories remain possible.
The fundamental structures in science (physics, chemistry, biology, etc.) sometimes elude us. They can appear mysterious, withholding some of their secrets and refusing the rules we try to impose upon them. Throughout history, conflicts between new theories, experimental data, and established beliefs have often been ignored or dismissed because they did not fit the accepted way of thinking. This attitude is frequently reflected in phrases such as “everyone knows” or “everyone should know.”
Discarding new ideas prematurely can be costly in the long run and, in our view, is almost always a mistake.
Of course, new theories must be tested rigorously, but the same standard must also apply continuously to existing theories. If we fail to do this, we risk leaving the path of science and moving instead toward complacency.
In physics, for example, we know about the coexistence of Albert Einstein’s relativity and Werner Heisenberg’s quantum mechanics. Both are experimentally successful in their domains, but the problem is that they are difficult to reconcile completely under one unified framework.
The question emerging for us was: "Can cryptography hold possibilities which would allow different theorems to co-exist, generating ciphers in compliance with Shannon's mathematical proof of Perfect Secrecy, I(P;C)=0." For this reason we put a question in front of 6 AI systems and 5 academics (mathematicians teaching at universities). The question will lead us back to Claude Shannon and his mathematical-theoretical proof of Perfect Secrecy and also the three axioms he formulated for his entropy function H:
Let's assume we have a plaintext string of random characters and a key string that only consists of 26 characters. The plaintext uses the same alphabet as the key string, but is 10.000 random characters in length. How would an attacker try to crack a cipher created, using modular arithmetic and what would be the result of this attempt?
The answers we received from the academics were without exception that the cipher would provide no reasonable information for an attacker. The AI systems answered to the contrary, insisting that Claude Shannon's mathematical theoretical framework and his entropy H function would be enough to decrypt the cipher and produce the correct random string of random (don't forget random means unpredictable) characters. However, after the additional question to show us the pattern and frequencies that would emerge which they claimed would appear, they joined the consensus that it was impossible to solve the problem we presented with our question.
This moves us back to Claude Shannon and the three axioms he postulated for his evaluation of the Vernam Cipher (re-branded OTP later) and the four key requirements which you will not find in his papers. These requirements were a later addition by mathematicians and cryptographers for pedagogical or educational teaching purposes.
1. A key that is truly random
2. A Key as long as "All" messages to be sent
3. Each part of the Key is only used once
4. The Key is kept completely secret
Shannon's entropy function H (3 axioms) explaining function H to be a measure of a message A and the information it contains:
1. It should be continuous in the P(ai), where P is a probability.
2. It increases monotonically with N if P(ai) = 1/N
3. It satisfies the decomposition rule for joint entropy of two discrete random variables.
One sentence we found missing in Shannon's papers, which have been re-published and interpreted on different websites to explain his entropy H function and its connection with the Vernam system and the required Markov process:
*You will find it in "A Mathematical Theory of Cryptography, Claude E. Shannon — Published September 1945", which was one precursor to the final version published in the Bell System Technical Journal in October 1949.
"With N = 1 any letter is clearly possible and has the same a posteriori probability as its a priori probability. For one letter the system is perfect."
The reasons for its removal are unknown to us, but the sentence triggers for us an important and genuinely thought-provoking question:
"If each plaintext character is transformed independently through its own permutation space, without statistical dependence on neighboring characters, does the system still behave like one large Vernam system — or like many isolated one-symbol Vernam systems? And how does it affect the key requirements?"
Let's go back to Shannon and what he said:
11 EQUIVOCATION (Page 683 -- A Mathematical Theory of Cryptography)
Let us suppose that a simple substitution cipher has been used on English text and that we intercept a certain amount, N letters, of the enciphered text. For N fairly large, more than say 50 letters, there is nearly always a unique solution to the cipher; i.e., a single good English sequence which transforms into the intercepted material by a simple substitution. With a smaller N, however, the chance of more than one solution is greater: with N = 15 there will generally be quite a number of possible fragments of text that would fit, while with N = 8 a good fraction (of the order of 1 8) of all reasonable English sequences of that length are possible, since there is seldom more than one repeated letter in the 8. With N = 1 any letter is clearly possible and has the same a posteriori probability as its a priori probability. For one letter the system is perfect.
Does the paragraph not point to Shannon’s concern about language statistics and Markov dependencies? In ordinary language, letters are correlated, words are correlated and structure leaks information. His paper rigorously defines perfect secrecy as the condition where a ciphertext provides no information about the plaintext, which is mathematically true for a single character encrypted with a unique, random key (like in a One-Time Pad), but also true for a single transposed character using a random permutation of the alphabet. The paper also discusses the use of a "suitable Markoff process" to model the statistical properties of the message source and the key source.
Our argument for our transposition system is, if every symbol transformation is isolated, and no transition information propagates between neighboring symbols, then higher-order statistical structure will collapse. That is a serious conceptual point one has to explore.
Here is a more conceptual answer to our question we formulated above.
In an isolated one-symbol system with each character encrypted independently with its own key (permutation), the security of each character is identical to that of a single-character Vernam cipher. The ciphertext for one character reveals nothing about that specific plain character, just as in a perfect one-symbol system.
In a large Vernam system, when we combine all these independent encryptions, the overall system is mathematically equivalent to a standard Vernam system (OTP) applied to the entire message. The "key" for a large system is simply the concatenation of all the individual keys (or permutations) used for each character. The requirement for perfect secrecy, that the key space is at least as large as the message space and is used only once, is fully satisfied.
Therefore, the system achieves perfect secrecy as defined by Shannon. The independence of the permutations ensures that the statistical properties of the plaintext (like letter frequency) are completely masked, and an attacker, even with infinite computational power, cannot determine the original message from the ciphertext alone, as every possible plaintext of the same length remains equally probable.
